How to Choose the Right LLM for Your Specific Workflow

Let’s be real. Every week there’s a new "king" of the AI hill. One day it’s the top performer for coding, and the next, it’s a new heavyweight for creative writing. If you’re a business leader or an engineer, chasing the latest shiny model is a one-way ticket to burnout. You don’t need the most famous model; you need the one that actually works for your stack.
Stop picking models based on "vibes" and start treating them like any other critical infrastructure. Your workflow has specific constraints—budget, data privacy, or raw speed. Today, we’re cutting through the noise to help you build a strategy that sticks.
The Trap of "Model Hopping"
Many teams fall into the "model hopping" trap. They see a leaderboard, switch their API, and then wonder why their latency spiked or their output quality took a nosedive. This chaos usually stems from ignoring LLM vendor lock-in risk management during the early procurement phase.
When you treat AI models as interchangeable commodities, you’re setting yourself up for a headache. Different architectures excel at different tasks. For example, a model tuned for heavy reasoning might be complete overkill—and way too expensive—for a simple summarization task.
Why Benchmarks Can Be Deceiving
Public benchmarks are like sports stats. They show you what a model can do under perfect lab conditions. They rarely show you how the model handles your messy, real-world data.

If you’re building an LLM evaluation framework for enterprise use, don’t rely solely on general benchmarks like MMLU or HumanEval. They don’t know your business. Instead, you need to test the model against your own internal constraints.
Defining Your "In-Domain Gold Set"
If you take one thing away from this guide, let it be this: build an in-domain gold set for AI testing. This isn't just a "best practice." It’s a requirement for survival.
Gather 50 to 500 examples of real inputs your system receives. These should include your "tricky" edge cases—the ones that usually make your current setup stumble. By running these inputs through various models, you get a side-by-side comparison that actually matters.
- Create a baseline: Use your current best-performing model as the control.
- Identify failure modes: Is it failing on tone? Is it hallucinating facts? Or is it just too slow?
- Score the output: Assign a simple 1–5 rating based on utility, not just "smartness".
When you have a gold set, you stop guessing. You start measuring.
Calculating the True Total Cost of Ownership
We often obsess over the cost per 1,000 tokens. That’s a mistake. The total cost of ownership for generative AI goes far beyond the API bill.
Consider the "hidden" costs:
- Maintenance: How much time does your team spend tweaking prompts for this specific model?
- Latency: If a model takes five seconds longer to respond, how many customers bounce?
- Governance: Does this model meet your security requirements? Are you paying extra for a private instance or a VPC?
Sometimes, paying a premium for a "smarter" model actually saves money because you can use a shorter, simpler prompt. That’s a classic trade-off. Think about it.
Benchmarking LLMs for Business Applications
When benchmarking LLMs for business applications, you need to think like a product manager, not a researcher. You aren't trying to advance the state of the art; you're trying to solve a problem.
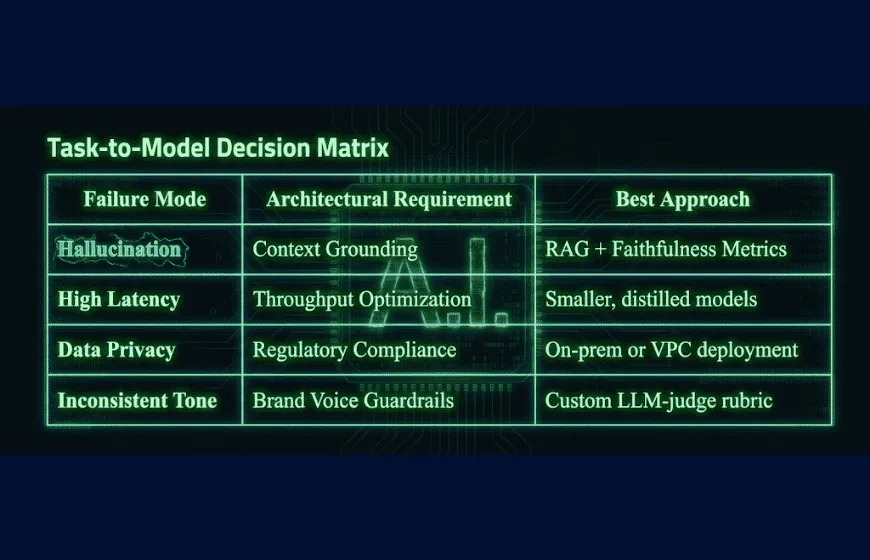
By segmenting your workload, you avoid wasting budget on tasks that don't need a Ferrari engine to get the job done.
Avoiding the Lock-in Trap
The biggest risk isn't choosing the wrong model today. It’s failing to build a system that lets you swap models tomorrow. If your code is tightly coupled to one vendor’s specific API quirks, you’re in trouble.
Build an abstraction layer—an AI gateway. Keep your prompt logic separate from your model-calling code. This gives you the flexibility to pivot when a better, cheaper, or more compliant model hits the market. It’s about keeping your options open, not staying married to the first provider you hired.
Build for Evolution
Choosing the right AI model isn't a one-time event. It’s a continuous process of auditing and improvement. Start by building your gold set, calculate your real costs, and always design for modularity.
The landscape is changing fast. Don’t get stuck in the weeds of technical vanity metrics. Keep your eyes on the business outcomes. That’s how you actually win.
Frequently Asked Questions (FAQ)
How can I tell if a model is "hallucinating" without manually reading every output?
You need to implement automated evaluation frameworks. By using a "judge" model—a stronger model that evaluates the outputs of a smaller, faster model—you can check for factual consistency against your source documents. It’s not perfect, but it’s a heck of a lot faster than doing it by hand.
Is it better to fine-tune an open-source model or use an API-based commercial model?
It depends on your data privacy needs and your team’s capacity. Fine-tuning an open-source model gives you total control, but you own the infrastructure costs. Commercial APIs are easier to set up but tie you to a vendor's roadmap. Start with an API and only move to custom tuning if you hit a performance wall you can't climb over with prompt engineering.
How often should I re-evaluate my LLM choice after initial deployment?
At least once a quarter. Model performance can "drift" as providers update their underlying versions. Keep your evaluation pipeline active. When a new model drops, run it against your gold set. If it beats your current model on quality-per-dollar, don't hesitate to switch. Stay nimble.